The ML special interest group at the Indian Institute of Science organised a talk by Mr Mayur Thakur and Sreenath Maikkara (Goldman Sachs). Here is a summary of the talk and the key takeaways as interpreted by me.
Speaker Bio: Mayur Thakur is head of the Surveillance Analytics Group in the Global Compliance Division. The Group serve as quantitative experts designing and implementing risk-based surveillances models, on large scale data of the firm. He joined Goldman Sachs as a managing director in 2014. Prior to joining the firm, Mayur worked at Google, where he designed search algorithms for more than seven years. Previously, he was an assistant professor of computer science at the University of Missouri.
The team presenting here, the surveillance team is part of a bigger block called the compliance team. This talk was a wonderful opportunity for me to understand the applications of machine learning and data science in general in the fin tech world.
The speaker started the talk by mentioning how the stakes were pretty high in the financial markets.
- Fines imposed on corporations are disproportionate to the amount of money made committing the offence.
- The number of regulators in the market is pretty high. As these companies have international operations in different markets, they have to deal with multiple regulators in each of these markets.
The main thesis of the speaker that he wanted his audience to take away was that “Building the data pipeline is much more difficult than applying a machine learning algorithm on it”, which sounded ridiculous at the start especially to someone working on ML algorithms in a research setting but as the talk progressed, the thesis started to make sense.
The key challenges faced by their team, which I am extrapolating to be true across the fin tech world are as follows:
- Diverse data sets and formats: Data is collated from diverse sources and each of these sources have their own set of formats that they follow. For example the European desk may follow a different schema when compared to the Tokyo desk.
- The size of the data that they have to deal with is huge and it is updated very frequently.
- Data from the past can change: This can happen in multiple scenarios one of them being when a manual trade correction is made, your pipeline needs to be built in such a way so that these kind of changes can flow through it without breaking the system.
- Surveillance decisions need to be debuggable: This is mostly because of the regulations, one fine day the feds may come knocking on your day asking ‘Why was trade X on Oct 25 2015 not flagged’ and you need to have enough data to be able to explain those decisions taken by your algorithm.
- Not real time but need some time guarantees are needed (say T+1).
There are multiple lines of defence. Each transaction goes through the stack shown below, but generally speaking you don’t want the SEC to come knocking at your doorstep (public safety tip)

The architecture that the team uses to overcome these challenges is shown below.
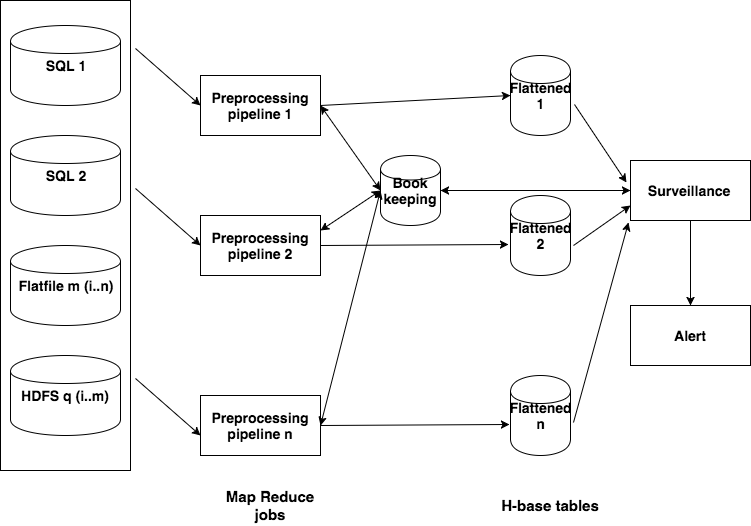
The Preprocessing pipeline is basically a map reduce job. Each of the Flattened table is a H base table.
This architecture combats the key challenges in the following manner:
- Diverse datasets & formats -> Preprocessing + common format
- Size of data -> Hadoop + preprocessing
- Data from past changes -> Hbase + versioning
- Decisions need to be debuggable -> Bookkeeping
- Time guarantees -> MapReduce
Spoofing a case study
To understand the kind of problems that the surveillance team seeks to remedy are diverse, spoofing is a good representative example of this set.
What is spoofing:
You want to sell 300 shares of XYZ at a high price
Artificially inflating the price before you sell would earn a nice profit
Exchanges allow you to submit orders and later cancel them. If you submit many ‘ spoofs’ (fake orders) buy orders first. You’ll create an illusion of buying pressure, to drive up the price.
You then sell your 300 shares of XYZ and then quickly cancel the many fake buy orders.
One of the unique challenges in solving this problem and detecting such transaction is the lack of training data. So supervised training cannot be used in this scenario. The Goldman Sachs team analysed 6 regulatory enforcement cases and identified 4 characteristic features of transactions that attempt spoofing:
Order imbalance
Time to cancel post execution < 1 sec
Level of profit generated by the trades
Marketability
No model for you
The model developed by GS is proprietary and not meant for public consumption (booo)
This talk provided me with key insights into how the FinTech world works, hope this blog post does the same for you. A lot of my assumptions were challenged, for instance who knew that markets around the world could not agree on time, creating the missing millisecond problem.
Apparently some of the exchanges do not keep track of the milliseconds when timestamping the trades wreaking havoc on algorithms such as the one developed by GS to detect spoofing as in the world of algorithmic trading the market changes in milliseconds and they need to keep track of the millisecond on the timestamp to classify a trade as spoofing. Saved by a millisecond.